Некоторое время назад для нас в полный рост встала проблема восстановления баз данных на тестовые стенды из-за значительно увеличивающегося времени, которое эта процедура стала занимать.
После некоторых размышлений было решено взять отдельный физический сервер, развернуть на нем в качестве файловой системы ZFS и организовать воостановление баз через клонирование разделов из снапшотов, также известные как "мгновенные снимки состояние системы", которые в ZFS, в отличие от других реализаций, сделаны шикарно.
Мы перенесли наши тестовые стынды на этот сервер, после чего переписали процедуру восстановления. Теперь когда программисты нажимают кнопочку "Восстановить БД на стенде Х" - эта процедура занимает от 2 до 6 минут.
Парочка цифр для понимания масштаба изменений:
- - Ранее восстановление всех баз данных на одном стенде занимал от 8 до 10 часов, то бишь всю ночь.
- Из времени восстановление - непосредственно копирование данных базы занимало 90% времени.
- Нынешнее восстановление на одном стенде занимает 2-6 минут.
- Непосредственно копирование баз данных из этого времени занимает 3 секунды. Остальное время занимает исполнение скриптов для подготовки на стенде определенного функционала, необходимого разработчикам.
Общая схема работы выглядит следующим образом:
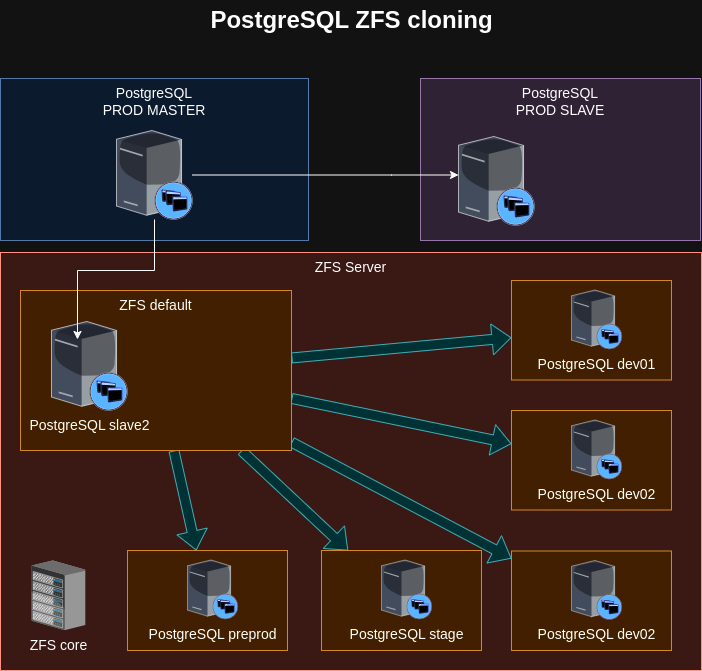
- Помимо уже устоявшейся связки "два одинаковых сервера мастер-слейв", где на мастер пишутся данные, а из слейва иногда читается часть данных (а также он играет роль резерва, на случай отказа мастера), теперь у нас появился еще один "слейв", который находится на вышеупомянутом сервере и складывает содержимое прода в отдельный раздел с именем "postgres-default".
- После чего при нажатии кнопочки "восстановить базу сенда Х" запускается удаление текущего состояния баз, создание снапшота (сохранение текущего состояния базы данных), а затем создание нового раздела для базы стенда, который является дочерним от этого снапшота и уже содержит все сохраненные данные с прода.
- Остается только прогнать скрипты для удаления лишних продовых данных, добавлении тестовых и некоторые другие изменения.
Неожиданным бонусом такой схемы стало усиление сохранности данных с прода, так как у нас появляется новое место с сохранением состояния прода, которое можно снапшотить произвольное количество раз. А значит у нас останется это состояние в будущем и, при необходимости, мы можем восстановить любое из них. Это позволяет нам иметь еще один "круг" резервных копий на случай катастрофы и отказа как мастера, так и слейва и уже имеющихся резервных копий. А также позволяет нам мгновенно сохранить состояние прода. Например, чтобы обезопасить себя перед опасными действиями на проде, запускать тяжелые запросы или обновлять приложения с миграциями, и при этом не ждать долгих бекапов. Правда восстановление из ZFS снапшота займет некоторое время, так как автоматизации для этого процесса на данный момент нет. Это не являлось целью этих работ пока что.
На данный момент есть несколько нерешенных проблем с этой процедурой, но мы в процессе их решения. Например, оптимизация потребления ресурсов базами разных стендов. Также мы улучшаем процедуру обфускации, чтобы на тестовых стендах не оставалось никаких настоящих пользовательских данных гарантированно.